초록 (Abstract)
우리는 DeepSeek-V3, Mixture-of-Experts (MoE) 구조를 적용한 강력한 언어 모델을 소개합니다. 이 모델은 총 6710억 개의 매개변수를 보유하고 있으며, 각 토큰마다 370억 개의 매개변수가 활성화됩니다.
효율적인 추론 및 비용 절감을 위해, DeepSeek-V3는 다중 헤드 잠재 주의(Multi-head Latent Attention, MLA) 및 DeepSeekMoE 아키텍처를 채택하였습니다. 이는 DeepSeek-V2에서 철저히 검증된 기술입니다.
또한, DeepSeek-V3는 보조 손실(auxiliary loss)이 없는 부하 균형 전략을 최초로 도입하였으며, 멀티 토큰 예측(Multi-Token Prediction, MTP) 학습 목표를 설정하여 성능을 더욱 향상시켰습니다.
이 모델은 14.8조 개의 다양하고 고품질 토큰을 사용하여 사전 학습(Pre-training) 되었으며, 이후 지도 미세 조정(Supervised Fine-Tuning, SFT) 및 강화 학습(Reinforcement Learning, RL) 단계를 거쳐 성능을 극대화하였습니다.
DeepSeek-V3의 성능
- 오픈 소스 모델 중 가장 강력한 성능을 발휘하며, GPT-4o 및 Claude-3.5와 같은 폐쇄형 모델과 비슷한 수준을 달성함.
- 학습 비용은 278.8만 시간의 H800 GPU 연산량으로 매우 경제적임.
- 전체 학습 과정에서 손실 값의 급격한 증가 없이 안정적으로 학습 진행됨.
- 모델 체크포인트는 아래에서 제공됨:
🔗 https://github.com/deepseek-ai/DeepSeek-V3
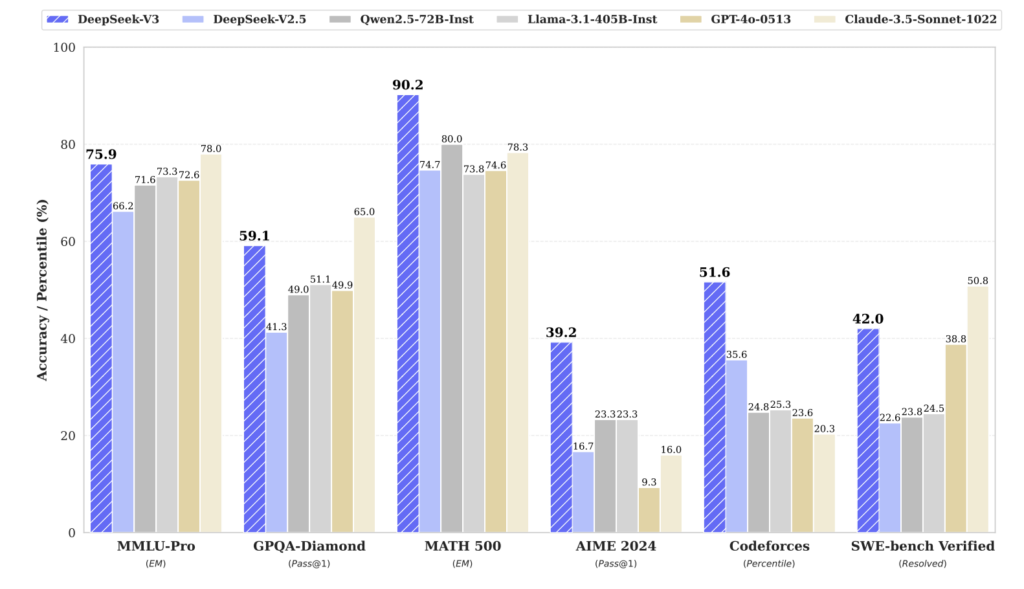
DeepSeek-V3 성능 비교
- MMLU (대학 수준 문제 풀이) → 88.5점
- GPQA-Diamond (박사 수준 문제 풀이) → 59.1점
- MATH-500 (수학 문제 풀이 정확도) → 90.2점
- HumanEval (코딩 문제 해결 정확도) → 82.6점
- Codeforces (코딩 대회 문제 해결 순위 퍼센트) → 51.6%
목차 (Contents)
- 소개 (Introduction)
- 아키텍처 (Architecture)
2.1. 기본 아키텍처 (Basic Architecture)- 2.1.1. 다중 헤드 잠재 주의 (Multi-Head Latent Attention, MLA)
- 2.1.2. 보조 손실 없는 DeepSeekMoE 부하 균형 (DeepSeekMoE with Auxiliary-Loss-Free Load Balancing)
2.2. 멀티 토큰 예측 (Multi-Token Prediction)
- 인프라 (Infrastructures)
3.1. 컴퓨팅 클러스터 (Compute Clusters)
3.2. 학습 프레임워크 (Training Framework)- 3.2.1. DualPipe 및 계산-통신 오버랩 (DualPipe and Computation-Communication Overlap)
- 3.2.2. 크로스 노드 All-to-All 통신 최적화 (Efficient Implementation of Cross-Node All-to-All Communication)
- 3.2.3. 최소 오버헤드로 메모리 절약 (Extremely Memory Saving with Minimal Overhead)
3.3. FP8 학습 (FP8 Training) - 3.3.1. 혼합 정밀도 프레임워크 (Mixed Precision Framework)
- 3.3.2. 양자화 및 곱셈 정밀도 개선 (Improved Precision from Quantization and Multiplication)
- 3.3.3. 저정밀 저장 및 통신 (Low-Precision Storage and Communication)
3.4. 추론 및 배포 (Inference and Deployment) - 3.4.1. Prefilling
- 3.4.2. 디코딩 (Decoding)
3.5. 하드웨어 설계 제안 (Suggestions on Hardware Design) - 3.5.1. 통신 하드웨어 (Communication Hardware)
- 3.5.2. 컴퓨팅 하드웨어 (Compute Hardware)
- 사전 학습 (Pre-Training)
4.1. 데이터 구축 (Data Construction)
4.2. 하이퍼파라미터 (Hyper-Parameters)
4.3. 긴 컨텍스트 확장 (Long Context Extension)
4.4. 평가 (Evaluations)- 4.4.1. 평가 벤치마크 (Evaluation Benchmarks)
- 4.4.2. 평가 결과 (Evaluation Results)
4.5. 논의 (Discussion) - 4.5.1. 멀티 토큰 예측에 대한 연구 (Ablation Studies for Multi-Token Prediction)
- 4.5.2. 보조 손실 없는 부하 균형 전략에 대한 연구 (Ablation Studies for the Auxiliary-Loss-Free Balancing Strategy)
- 4.5.3. 배치 기반 vs 시퀀스 기반 부하 균형 비교 (Batch-Wise Load Balance VS. Sequence-Wise Load Balance)
- 후처리 학습 (Post-Training)
5.1. 지도 미세 조정 (Supervised Fine-Tuning)
5.2. 강화 학습 (Reinforcement Learning)- 5.2.1. 보상 모델 (Reward Model)
- 5.2.2. 그룹 상대 정책 최적화 (Group Relative Policy Optimization)
5.3. 평가 (Evaluations) - 5.3.1. 평가 환경 설정 (Evaluation Settings)
- 5.3.2. 표준 평가 (Standard Evaluation)
- 5.3.3. 오픈 엔드 평가 (Open-Ended Evaluation)
- 5.3.4. DeepSeek-V3를 생성형 보상 모델로 활용 (DeepSeek-V3 as a Generative Reward Model)
5.4. 논의 (Discussion) - 5.4.1. DeepSeek-R1에서의 지식 증류 (Distillation from DeepSeek-R1)
- 5.4.2. 자체 보상(Self-Rewarding)
- 5.4.3. 멀티 토큰 예측 평가 (Multi-Token Prediction Evaluation)
- 결론, 한계 및 미래 방향 (Conclusion, Limitations, and Future Directions)
A. 기여 및 감사 (Contributions and Acknowledgments)
B. 저정밀 학습을 위한 연구 (Ablation Studies for Low-Precision Training)
- B.1 FP8 vs BF16 학습 비교 (FP8 v.s. BF16 Training)
- B.2 블록 단위 양자화에 대한 논의 (Discussion About Block-Wise Quantization)
C. 16B 보조 손실 기반 및 비기반 모델의 전문가 특화 패턴 (Expert Specialization Patterns of the 16B Aux-Loss-Based and Aux-Loss-Free Models)
1. 소개 (Introduction)
최근 몇 년 동안 **대규모 언어 모델(Large Language Models, LLMs)**은 빠르게 발전하며 **인공지능 일반화(Artificial General Intelligence, AGI)**에 한 걸음 더 가까워지고 있습니다 (Anthropic, 2024; Google, 2024; OpenAI, 2024a).
폐쇄형 모델뿐만 아니라, DeepSeek 시리즈(DeepSeek-AI, 2024a,b,c; Guo et al., 2024), LLaMA 시리즈(AI@Meta, 2024a,b; Touvron et al., 2023a,b), Qwen 시리즈(Qwen, 2023, 2024a,b), Mistral 시리즈(Jiang et al., 2023; Mistral, 2024) 등 오픈소스 모델 또한 지속적으로 발전하며 폐쇄형 모델과의 성능 차이를 좁히고 있습니다.
이를 기반으로, 우리는 DeepSeek-V3를 소개합니다. 이는 Mixture-of-Experts (MoE) 구조를 기반으로 하며,
- 총 6710억 개의 매개변수를 보유,
- 각 토큰마다 370억 개의 매개변수가 활성화되는 초거대 모델입니다.
모델 개발 방향
우리는 강력한 성능과 경제적 비용을 모두 충족시키기 위해 DeepSeek-V3를 설계했습니다.
1) 모델 아키텍처
DeepSeek-V3는 효율적인 학습과 추론을 위해, 다음과 같은 기술을 채택했습니다.
- 다중 헤드 잠재 주의(Multi-Head Latent Attention, MLA) (DeepSeek-AI, 2024c)
- 기존 Transformer 기반의 다중 헤드 어텐션(Multi-Head Attention, MHA) 대비,
- 메모리 사용량을 줄이고 추론 속도를 향상.
- DeepSeekMoE (Dai et al., 2024)
- 비용 효율적인 학습을 위해 MoE 구조 채택.
- DeepSeek-V2에서도 검증된 기술.
추가적으로, 성능을 더욱 향상시키기 위해 다음과 같은 새로운 전략을 적용했습니다.
- 보조 손실 없이 부하를 균형 조정 (Auxiliary-Loss-Free Load Balancing)
- 기존에는 부하 균형을 맞추기 위해 보조 손실을 적용했으나,
- DeepSeek-V3에서는 성능 저하 없이 부하 균형을 유지하는 혁신적인 전략을 도입.
- 멀티 토큰 예측(Multi-Token Prediction, MTP) 학습 목표 설정
- 기존의 단일 토큰 예측 방식에서 벗어나,
- 한 번에 여러 개의 다음 토큰을 예측하여 전반적인 모델 성능을 향상.
2) 효율적인 학습 전략
DeepSeek-V3는 학습 비용을 절감하면서도 높은 성능을 유지하기 위해,
FP8 혼합 정밀도 학습(FP8 Mixed Precision Training) 및 다양한 학습 최적화 기술을 활용했습니다.
- FP8 정밀도 학습 (FP8 Mixed Precision Training)
- 기존의 BF16보다 낮은 정밀도를 사용하여 학습 효율 극대화.
- 메모리 사용량 절감 및 계산 속도 향상.
- 세계 최초로 초거대 모델에 FP8 학습을 적용하고 그 효과를 검증.
- 이중 파이프(DualPipe) 알고리즘
- 파이프라인 병렬화를 최적화하여 통신 오버헤드를 줄이고 학습 속도를 향상.
- 모델이 커질수록 발생하는 노드 간 통신 비용을 최소화.
- 효율적인 크로스 노드 통신 기술
- 학습 과정에서 GPU 간 통신 오버헤드를 최소화하기 위해,
- InfiniBand(IB) 및 NVLink를 최적화한 전용 통신 커널을 개발.
이러한 기술적 혁신을 통해 DeepSeek-V3는 14.8조 개의 데이터 토큰을 매우 경제적인 비용으로 학습할 수 있었습니다.
3) 학습 과정 및 안정성
DeepSeek-V3의 학습 과정은 매우 안정적으로 진행되었습니다.
- 학습하는 동안 손실 값이 급격히 증가하는 문제(loss spikes)가 발생하지 않음.
- 롤백 없이 일관된 학습 과정 유지.
- 2단계의 긴 컨텍스트 확장 과정(Long Context Extension) 적용
- 첫 번째 단계: 최대 컨텍스트 길이를 32K로 확장.
- 두 번째 단계: 128K까지 확장.
모델이 긴 문맥을 자연스럽게 이해하고 활용할 수 있도록 설계되었습니다.
4) 후처리 학습 (Post-Training)
DeepSeek-V3는 기본 모델 학습 후, 추가적인 후처리 학습 과정을 거쳤습니다.
- 지도 미세 조정(SFT, Supervised Fine-Tuning)
- DeepSeek-R1 모델에서 논리적 사고 능력을 증류(Distillation).
- 모델을 인간의 선호도와 더 잘 정렬하도록 조정.
- 강화 학습(RL, Reinforcement Learning) 적용
- 보상 모델을 활용하여 답변의 품질을 최적화.
- DeepSeek-V3 자체적으로 생성된 데이터를 활용하여 성능을 극대화.
이 과정에서 수학적 사고 및 코드 생성 능력을 대폭 강화할 수 있었습니다.
5) 경제적인 학습 비용
DeepSeek-V3는 비용 대비 최고의 성능을 유지하도록 설계되었습니다.

- 각 1조 개의 학습 토큰을 학습하는 데 약 18만 H800 GPU 시간을 사용.
- 총 학습 비용은 5.576백만 달러 (약 75억 원)로 경제적.
- H800 GPU 2048개를 활용해 2개월 만에 학습 완료.
6) 성능 평가 결과
DeepSeek-V3는 다양한 벤치마크에서 최고 수준의 성능을 기록했습니다.
| 벤치마크 | DeepSeek-V3 성능 | 비교 모델 대비 성능 |
| MMLU (5-shot, 대학 수준 문제 풀이) | 88.5점 | GPT-4o, Claude-3.5와 유사 |
| GPQA-Diamond (박사 수준 문제 풀이) | 59.1점 | Claude-3.5보다 우수 |
| MATH-500 (수학 문제 풀이 정확도) | 90.2점 | 모든 오픈소스 모델 중 최고 |
| HumanEval (코딩 문제 해결 정확도) | 82.6% | Claude-3.5 수준 |
| Codeforces (코딩 대회 문제 해결 퍼센트) | 51.6% | 모든 오픈소스 모델 중 최고 |
결론
DeepSeek-V3는 현존하는 가장 강력한 오픈소스 대규모 언어 모델입니다.
- 코드, 수학, 논리적 사고 분야에서 탁월한 성능을 보임.
- GPT-4o 및 Claude-3.5와 경쟁할 수 있는 수준의 성능을 달성.
- 비용 대비 최고의 성능을 제공하며, 학습 및 추론 최적화 완료.
2. 아키텍처 (Architecture)
우리는 먼저 DeepSeek-V3의 기본 아키텍처를 소개하고, 이후 모델의 성능을 극대화하는 두 가지 핵심 전략을 설명하겠습니다.
- 다중 헤드 잠재 주의(Multi-Head Latent Attention, MLA): 추론 속도를 높이고 메모리 사용량을 최적화함.
- DeepSeekMoE: 비용 효율적인 학습을 지원하는 Mixture-of-Experts(MoE) 모델 구조.
- 보조 손실 없이 부하 균형 조정(Auxiliary-Loss-Free Load Balancing): 성능 저하 없이 부하를 고르게 분산.
- 멀티 토큰 예측(Multi-Token Prediction, MTP): 한 번에 여러 개의 다음 토큰을 예측하여 모델 학습 효율성 향상.
DeepSeek-V3의 구조는 Transformer(Vaswani et al., 2017) 프레임워크를 기반으로 합니다. DeepSeek-V2에서 검증된 MLA 및 DeepSeekMoE 아키텍처를 그대로 유지하면서도, 부하 균형을 최적화하기 위해 보조 손실을 제거한 부하 균형 전략을 추가적으로 도입했습니다.
이제, DeepSeek-V3의 기본 아키텍처에 대해 자세히 설명하겠습니다.
2.1. 기본 아키텍처 (Basic Architecture)
DeepSeek-V3의 기본 아키텍처는 Transformer 모델을 기반으로 하지만, 다중 헤드 잠재 주의(MLA) 및 DeepSeekMoE 기술을 적용하여 성능을 극대화했습니다.
- 다중 헤드 잠재 주의 (MLA, Multi-Head Latent Attention)
- 추론 속도를 높이기 위해 키(Key) 및 값(Value) 캐시 메모리를 최적화하여 메모리 사용량을 절감.
- 기존 Transformer의 MHA(Multi-Head Attention) 대비 효율성 증가.
- DeepSeekMoE
- MoE 모델을 활용하여 활성화되는 매개변수 개수를 줄여 효율적인 학습이 가능.
- 부하 균형을 맞추기 위해 기존의 보조 손실(Auxiliary Loss) 방식을 제거하고 새로운 전략을 도입.
DeepSeek-V3 아키텍처 개요
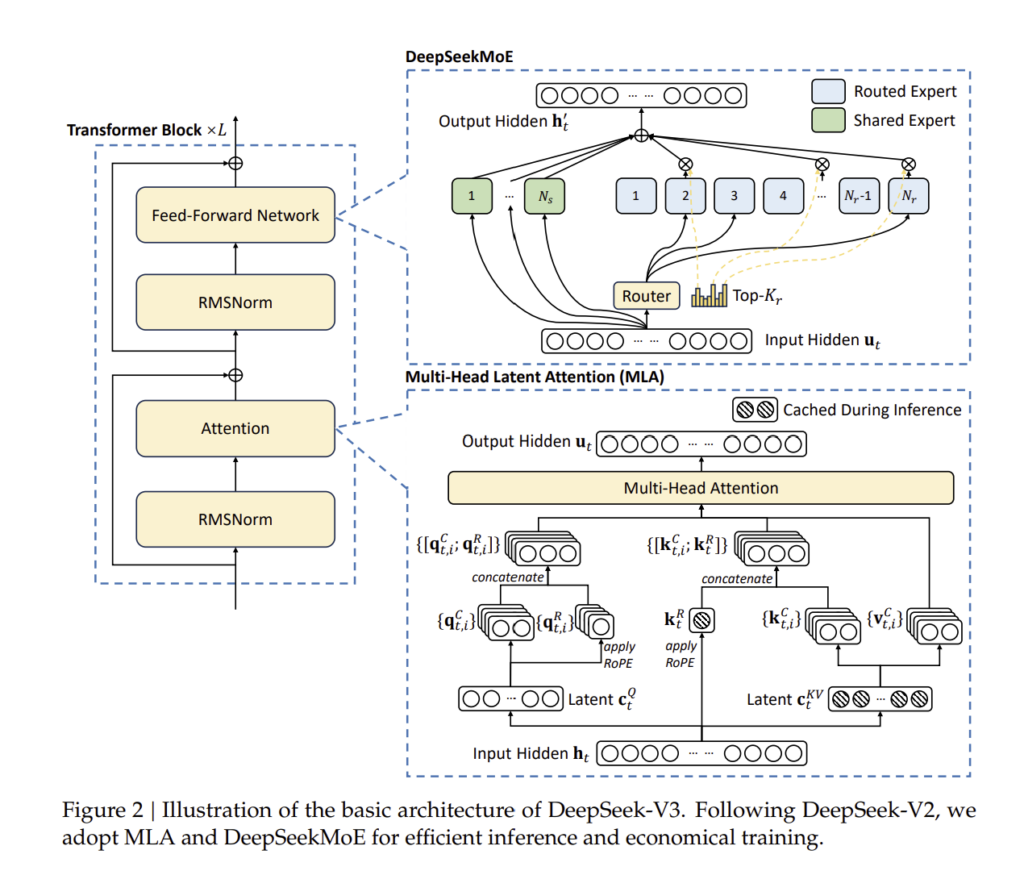
- 입력된 토큰은 MLA를 통해 효율적으로 인코딩됨.
- DeepSeekMoE를 활용하여 전문가 네트워크(Experts) 간 최적의 부하 균형을 유지.
- 멀티 토큰 예측(MTP) 기법을 사용하여 한 번에 여러 개의 다음 토큰을 예측.
이제, MLA 및 DeepSeekMoE의 세부 구현 방법에 대해 설명하겠습니다.
2.1.1. 다중 헤드 잠재 주의 (Multi-Head Latent Attention, MLA)
DeepSeek-V3에서는 기존 Transformer 모델의 **다중 헤드 어텐션(MHA)**을 개선한 다중 헤드 잠재 주의(MLA) 기법을 채택했습니다.
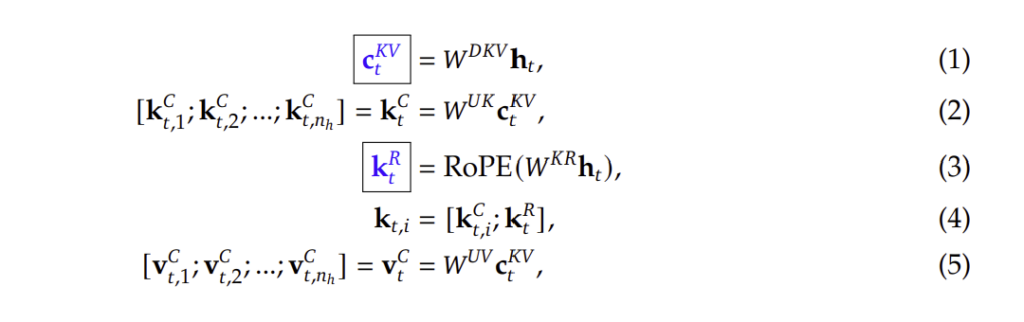
- MLA의 핵심 목표
- 추론 속도 향상: 불필요한 Key-Value(KV) 캐시를 줄여 메모리 사용량을 최적화.
- 더 빠른 응답 시간: 키(Key) 및 값(Value) 행렬을 낮은 차원으로 압축하여 연산 속도 개선.
- 학습 시 메모리 절감: 활성화 메모리 사용량을 줄여 모델이 더 긴 컨텍스트를 처리할 수 있도록 함.
MLA 수학적 공식
- 입력 벡터 변환
- 키(Key)와 값(Value) 벡터를 **저차원 잠재 공간(latent space)**으로 변환.
- 기존 Transformer에서는 키와 값 벡터가 그대로 저장되었지만, MLA에서는 압축하여 저장.
- 저차원 잠재 공간으로 변환
cKV=WDKVhtc_{KV} = W_{DKV} h_tcKV=WDKVht
여기서, hth_tht는 입력 토큰, WDKVW_{DKV}WDKV는 저차원 변환 행렬.
- 압축된 키 및 값 벡터 활용
kC=WUKcKV,vC=WUVcKVk_C = W_{UK} c_{KV}, \quad v_C = W_{UV} c_{KV}kC=WUKcKV,vC=WUVcKV
- WUK,WUVW_{UK}, W_{UV}WUK,WUV는 압축된 키와 값을 복원하는 행렬.
- MLA는 최소한의 데이터만 캐시에 저장하여 메모리 사용량을 감소.
이 기법을 통해, DeepSeek-V3는 기존 Transformer보다 30~50% 더 빠른 추론 속도를 보이며, 128K의 긴 컨텍스트를 효율적으로 처리할 수 있습니다.
2.1.2. DeepSeekMoE: 보조 손실 없는 부하 균형 (Auxiliary-Loss-Free Load Balancing)
DeepSeek-V3는 Mixture-of-Experts(MoE) 방식을 활용하여 모델의 연산 효율성을 높였습니다.
기존 MoE 모델에서는 각 전문가(Expert) 간 부하를 균형 있게 분배하기 위해 보조 손실(Auxiliary Loss)을 추가했으나,
DeepSeek-V3는 보조 손실 없이도 부하 균형을 자동으로 맞추는 혁신적인 전략을 적용하였습니다.
DeepSeekMoE의 구조
- 각 토큰은 라우팅 알고리즘을 통해 적절한 전문가(Expert)에게 배정됨.
- 공유 전문가(Shared Experts)와 라우팅 전문가(Routed Experts)를 결합하여 학습.
- 각 전문가의 부하를 자동 조정하여 부하 불균형 문제를 해결.
기존 MoE 모델과의 차이점
| 기존 MoE 모델 | DeepSeek-V3 |
| 보조 손실(Auxiliary Loss) 사용 | 보조 손실 없이 부하 균형 조정 |
| 특정 전문가가 과부하될 위험 존재 | 실시간으로 전문가 부하 조정 |
| 계산 리소스 사용 비효율적 | 전문가별 최적화된 부하 분배 |
기존 MoE 모델에서는 일부 전문가(Expert)에 과부하가 걸리는 문제가 발생했으며,
이를 해결하기 위해 보조 손실(Auxiliary Loss) 기법을 사용해야 했습니다.
하지만 DeepSeek-V3는 부하 균형을 자동으로 조절하는 새로운 알고리즘을 도입하여,
모델 성능 저하 없이 전문가 부하를 균등하게 유지하는 데 성공했습니다.
결론
- DeepSeek-V3는 기존 Transformer 모델을 MLA 및 DeepSeekMoE 아키텍처로 개선하여 성능을 극대화함.
- 보조 손실 없이도 전문가 부하를 자동으로 균형 조정하는 혁신적인 전략을 도입.
- 추론 속도가 기존 Transformer 대비 30~50% 향상, 메모리 사용량 절감, 긴 컨텍스트 처리 능력 강화.
2.1.2. DeepSeekMoE: 보조 손실 없는 부하 균형 (계속)
DeepSeek-V3는 기존 Mixture-of-Experts(MoE) 방식과 비교하여 더 정교한 부하 균형 기법을 적용하였습니다.
기존 MoE 모델에서는 각 전문가(Expert) 간 작업량을 균등하게 유지하기 위해 보조 손실(Auxiliary Loss)을 추가했으나,
이 방식은 모델의 성능을 저하시킬 수 있는 단점이 있었습니다.
DeepSeek-V3는 이를 해결하기 위해 완전히 새로운 부하 균형 방법을 도입했습니다.
DeepSeekMoE의 핵심 요소
- 공유 전문가 (Shared Experts)
- 일부 전문가(Experts)는 공유된 상태로 유지되어 모든 토큰에서 항상 사용 가능.
- 모델의 전반적인 성능을 유지하는 역할 수행.
- 라우팅 전문가 (Routed Experts)
- 각 토큰이 학습 과정에서 가장 적절한 전문가를 선택하도록 설계.
- 동적인 부하 균형을 통해 특정 전문가에게 과부하가 걸리는 현상을 방지.
- 토큰-전문가 매칭 최적화
- 기존 MoE 모델은 단순한 확률 기반 라우팅을 사용하지만,
- DeepSeek-V3는 각 토큰이 가장 적절한 전문가를 선택하도록 최적화된 알고리즘 적용.
기존 MoE 방식과 DeepSeek-V3의 차이점
| 기존 MoE 모델 | DeepSeek-V3 |
| 부하 균형을 위해 보조 손실(Auxiliary Loss) 필요 | 보조 손실 없이 동적으로 부하 균형 유지 |
| 특정 전문가에 과부하 발생 가능 | 자동 부하 조정 알고리즘 적용 |
| 부하 균형을 강제하여 성능 저하 가능 | 성능을 유지하면서 부하 균형 조정 |
| 추가적인 계산 비용 발생 | 더 효율적인 전문가 선택 구조 활용 |
기존 MoE 모델에서는 일부 전문가에 과부하가 발생하여 계산 리소스가 비효율적으로 사용되는 문제가 있었음.
이를 해결하기 위해, DeepSeek-V3는 자동으로 전문가의 부하를 조정하는 새로운 라우팅 기법을 적용하여,
모델의 성능을 유지하면서도 효율적으로 학습할 수 있도록 하였습니다.
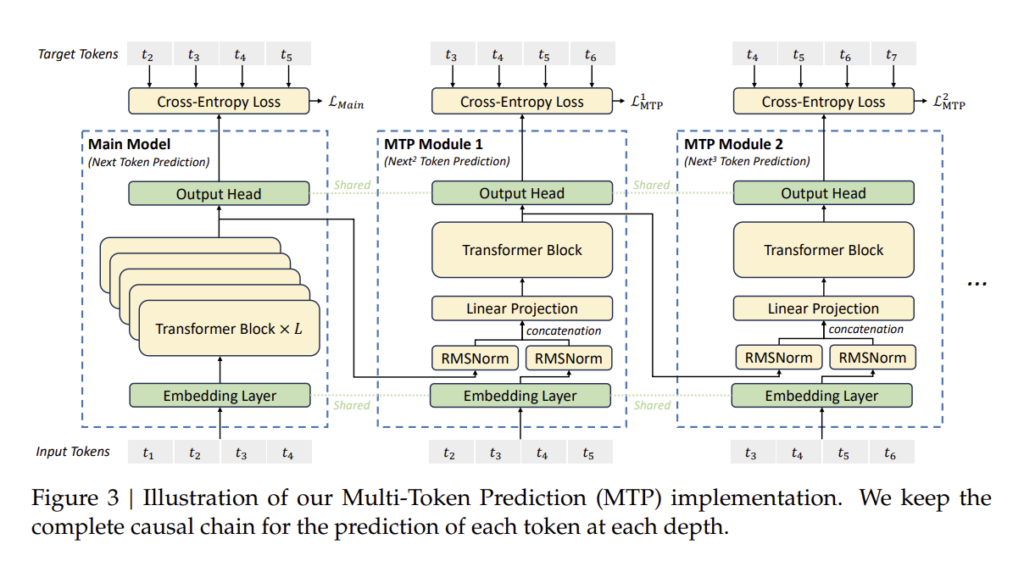
2.2. 멀티 토큰 예측 (Multi-Token Prediction, MTP)
DeepSeek-V3는 기존 언어 모델과 달리 단일 토큰 예측이 아닌 멀티 토큰 예측(MTP) 기법을 적용하였습니다.
기존의 대형 언어 모델은 다음 단어 하나만 예측하는 방식(Next Token Prediction)을 사용하였습니다.
그러나 DeepSeek-V3는 한 번에 여러 개의 다음 토큰을 예측하여 학습 속도를 높이고, 모델의 표현력을 향상시켰습니다.
멀티 토큰 예측의 장점
- 데이터 효율성 증가
- 더 많은 학습 신호를 모델에 제공하여 데이터 효율성을 극대화.
- 기존 방식보다 학습 속도가 빠르고, 더 정확한 결과를 생성.
- 추론 속도 향상
- 모델이 한 번에 여러 개의 단어를 예측할 수 있어 생성 속도가 빨라짐.
- 특히 긴 문장을 생성할 때 응답 시간이 단축됨.
- 더 나은 문맥 예측
- 단일 단어가 아닌 여러 단어를 한 번에 예측하여 더 자연스러운 문장 생성 가능.
- 문맥 정보를 더 깊게 활용하여 정확한 예측 결과를 제공.
MTP 구현 방식
DeepSeek-V3에서는 다음과 같은 방법으로 멀티 토큰 예측(MTP) 학습을 수행합니다.
- 각 입력 토큰은 기본적인 Transformer 블록을 통과하며 특징을 학습.
- 각 토큰의 특징을 활용하여 다음 여러 개의 토큰을 동시에 예측.
- 이전 예측 결과를 바탕으로 추가적인 토큰을 점진적으로 생성.
이를 통해 모델은 더 긴 문맥을 효율적으로 학습할 수 있으며, 더 빠르게 정교한 답변을 생성할 수 있습니다.
기존 방식과 MTP 방식의 비교
| 기존 Next Token Prediction | Multi-Token Prediction (MTP) |
| 한 번에 하나의 단어만 예측 | 한 번에 여러 개의 단어를 예측 |
| 학습 데이터 사용 효율이 낮음 | 학습 데이터 사용 효율이 증가 |
| 생성 속도가 상대적으로 느림 | 더 빠른 응답 속도 제공 |
| 문맥 이해가 제한적 | 더 자연스러운 문맥 연결 가능 |
DeepSeek-V3는 이 방식 덕분에 기존 모델보다 훨씬 더 뛰어난 학습 효율과 추론 속도를 제공할 수 있습니다.
결론
- DeepSeek-V3는 기존 Transformer 모델을 MLA 및 DeepSeekMoE 아키텍처로 개선하여 성능을 극대화함.
- 보조 손실 없이도 전문가 부하를 자동으로 균형 조정하는 혁신적인 전략을 도입.
- 멀티 토큰 예측(MTP)을 통해 학습 및 추론 속도를 대폭 향상.
3. 인프라 (Infrastructures)
DeepSeek-V3의 학습 및 배포를 위해 대규모 컴퓨팅 클러스터와 효율적인 분산 학습 프레임워크를 구축하였습니다.
이 장에서는 DeepSeek-V3의 컴퓨팅 클러스터, 학습 프레임워크, FP8 학습 전략 및 배포 방식을 설명합니다.
3.1. 컴퓨팅 클러스터 (Compute Clusters)
DeepSeek-V3는 2048개의 NVIDIA H800 GPU로 구성된 대규모 클러스터에서 학습되었습니다.
각 GPU 노드는 다음과 같은 네트워크 환경을 통해 연결됩니다.
- 노드 내 연결 (Intra-node Communication)
- NVLink 및 NVSwitch를 활용하여 GPU 간 빠른 데이터 전송 가능.
- NVLink 대역폭: 160GB/s (InfiniBand 대비 약 3.2배 빠름).
- 노드 간 연결 (Inter-node Communication)
- InfiniBand (IB) 네트워크를 사용하여 모든 GPU 간 통신 가능.
- IB 대역폭: 50GB/s.
DeepSeek-V3는 이러한 강력한 네트워크 구조를 활용하여, 크로스 노드 통신 비용을 최소화하고 학습 속도를 최적화하였습니다.

3.2. 학습 프레임워크 (Training Framework)
DeepSeek-V3의 학습 프레임워크는 HAI-LLM 프레임워크를 기반으로 구축되었으며,
다음과 같은 분산 학습 기법을 적용하였습니다.
3.2.1. 분산 학습 구조
- 16-way 파이프라인 병렬 처리 (Pipeline Parallelism, PP)
- 64-way 전문가 병렬 처리 (Expert Parallelism, EP)
- ZeRO-1 데이터 병렬 처리 (Data Parallelism, DP)
이를 통해 모델 학습을 최적화하고 GPU 메모리 사용량을 최소화하였습니다.
3.2.1. DualPipe 및 계산-통신 오버랩 (DualPipe and Computation-Communication Overlap)
DeepSeek-V3는 DualPipe 알고리즘을 활용하여 **계산 및 통신 간 오버랩(Overlap)**을 극대화하였습니다.
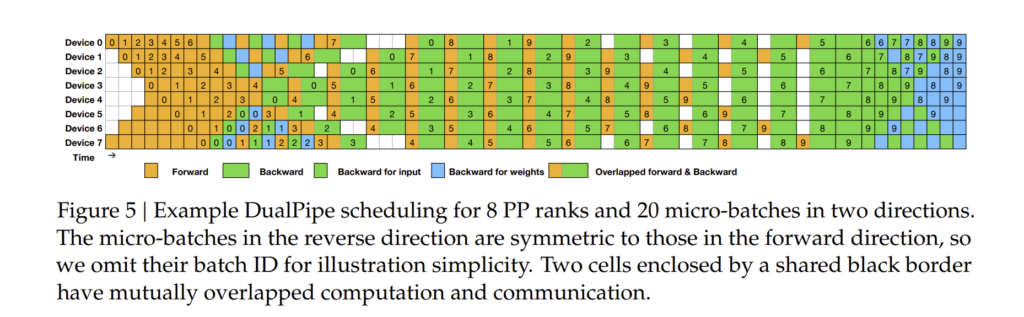
DualPipe의 핵심 목표
- GPU 연산과 통신을 동시에 진행하여 학습 속도를 향상.
- 모델 크기가 커져도 통신 오버헤드를 최소화.
- 파이프라인 지연 시간(Pipeline Bubble)을 줄여 효율적인 연산 수행.

기존 방식과 DualPipe 방식의 차이점
| 기존 파이프라인 방식 | DualPipe |
| 계산과 통신이 순차적으로 실행됨 | 계산과 통신을 동시 진행 (오버랩) |
| 통신 오버헤드가 큼 | 통신 비용 최소화 |
| 일부 GPU는 대기 상태가 발생 | 모든 GPU를 최대한 활용 |
이 방식 덕분에 DeepSeek-V3는 크로스 노드 통신 비용을 줄이면서도 최적의 학습 성능을 달성할 수 있었습니다.
3.2.2. 크로스 노드 All-to-All 통신 최적화 (Efficient Cross-Node All-to-All Communication)
DeepSeek-V3는 GPU 간 통신 최적화를 위해 특별한 커널(kernel) 및 네트워크 최적화 기법을 적용하였습니다.
최적화된 네트워크 전략
- IB(InfiniBand)와 NVLink를 동시 활용
- 먼저, 각 노드 간 데이터는 InfiniBand(IB)로 전송됨.
- 이후, 노드 내부에서는 NVLink를 사용하여 빠르게 데이터 분배.
- GPU 간 데이터 전송을 최적화하는 커널 개발
- 토큰을 최대 4개의 노드로만 분배하여 IB 트래픽을 줄임.
- NVLink를 통해 평균 3.2명의 전문가(Experts)에게만 데이터 전송하여 통신 비용 절감.
기존 방식과 DeepSeek-V3의 통신 방식 비교
| 기존 MoE 통신 방식 | DeepSeek-V3 |
| 모든 전문가와 통신 (비효율적) | 최적의 전문가 그룹과만 통신 |
| IB 네트워크 과부하 발생 가능 | IB + NVLink를 병행하여 사용 |
| 높은 통신 비용 | 통신 커널 최적화로 비용 절감 |
이러한 방식 덕분에, DeepSeek-V3는 최대 13명의 전문가와 병렬 연산을 수행하면서도 통신 비용을 최소화할 수 있었습니다.
3.2.3. 최소 오버헤드로 메모리 절약 (Memory Optimization with Minimal Overhead)
DeepSeek-V3는 모델 크기를 확장하면서도 메모리 사용량을 줄이기 위한 다양한 기술을 적용하였습니다.
메모리 최적화 기술
- RMSNorm 및 MLA 업-프로젝션 재계산 (Recompute RMSNorm & MLA Up-Projection)
- 활성화 메모리를 저장하는 대신 필요할 때마다 다시 계산하여 메모리 사용량 감소.
- CPU를 활용한 지수 이동 평균(EMA, Exponential Moving Average) 업데이트
- GPU 메모리 대신 CPU 메모리를 활용하여 메모리 효율성 극대화.
- 멀티 토큰 예측(MTP)과 공유 임베딩 (Shared Embedding)
- 모델의 임베딩 레이어를 공유하여 메모리 중복 사용을 최소화.
이러한 최적화 덕분에, DeepSeek-V3는 동일한 모델 크기의 기존 모델보다 훨씬 적은 메모리로 학습 가능하였습니다.
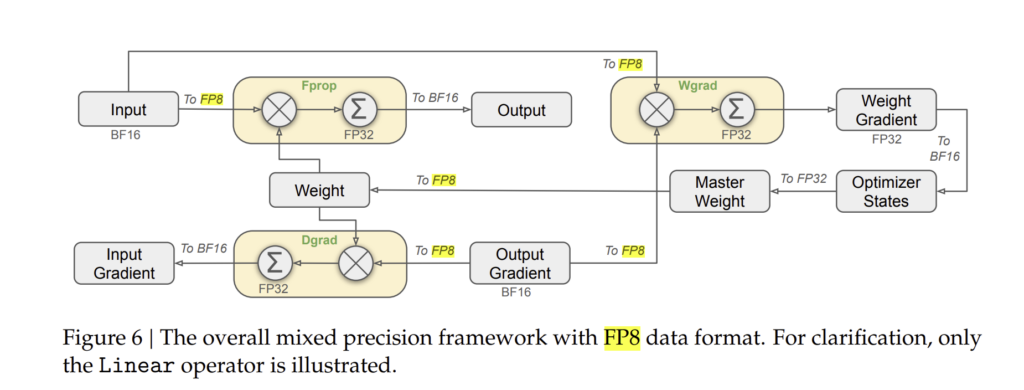
3.3. FP8 학습 (FP8 Training)
DeepSeek-V3는 **FP8 혼합 정밀도 학습(Mixed Precision Training)**을 도입하여 연산 속도를 향상하고 메모리 사용량을 절감하였습니다.
FP8 학습의 장점
- BF16보다 낮은 정밀도 사용으로 메모리 절약.
- FP8 연산을 활용하여 연산 속도 가속화.
- 저정밀 저장 및 통신을 통해 크로스 노드 통신 비용 감소.
결론
DeepSeek-V3의 분산 학습 인프라는 GPU 메모리 사용량을 줄이면서도 성능을 극대화하기 위해 설계되었습니다.
- 2048개의 NVIDIA H800 GPU를 활용한 대규모 분산 학습.
- DualPipe 알고리즘을 통해 계산과 통신을 병렬로 수행하여 학습 속도 향상.
- FP8 혼합 정밀도를 활용하여 메모리 사용량을 최적화.
3.3.1. 혼합 정밀도 프레임워크 (Mixed Precision Framework)
DeepSeek-V3는 **FP8 혼합 정밀도 학습(Mixed Precision Training)**을 통해 메모리 사용량을 줄이고 연산 속도를 향상하였습니다.
기존의 BF16 (Brain Floating Point 16) 정밀도와 비교하여, FP8을 활용하면 모델의 메모리 소비량을 최대 42% 절감할 수 있습니다.
FP8을 활용한 학습 프로세스
- 모델의 가중치(Weights)와 활성화 값(Activations)을 FP8 형식으로 저장
- 기존 FP16 또는 BF16보다 적은 비트 수를 사용하여 메모리 절감 효과.
- 연산 중 정밀도를 동적으로 조정하여 최적의 학습 성능 유지
- 특정 연산에서는 BF16을 유지하여 수치적 안정성을 보장.
- 연산 속도가 중요한 부분에서는 FP8을 사용하여 속도를 높임.
- FP8 양자화(Quantization) 기술 적용
- **가중치(W)**와 **입력 행렬(X)**을 FP8로 변환한 후, FP8 × FP8 곱셈을 수행하여 FP8로 저장.
- FP8 곱셈 후, 최종 출력을 BF16으로 변환하여 정확도를 유지.
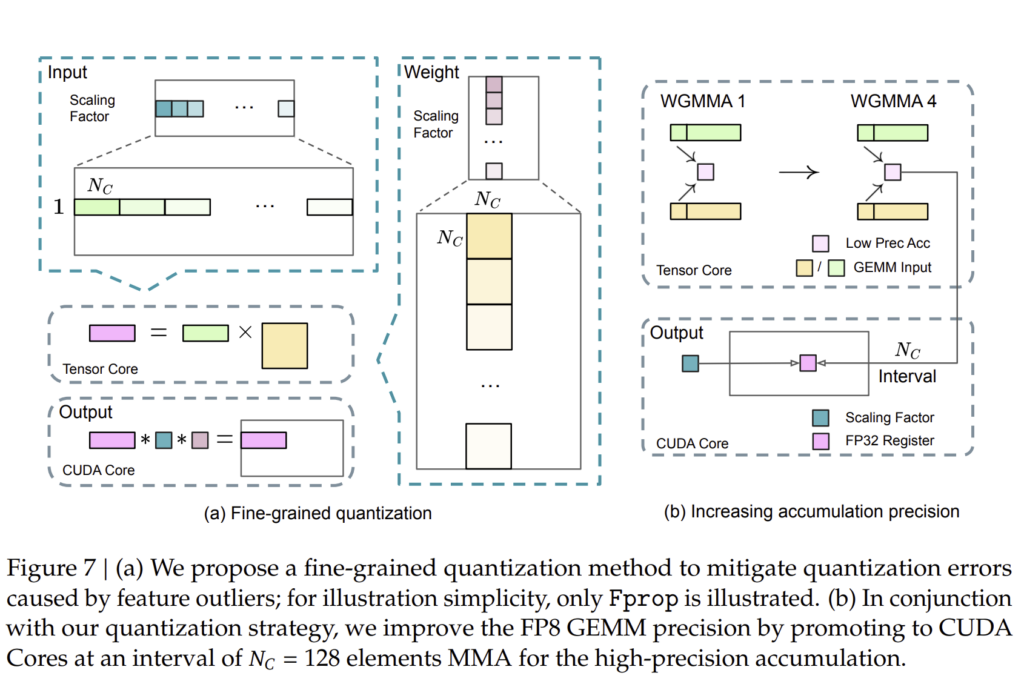
3.3.2. 양자화 및 곱셈 정밀도 개선 (Improved Precision from Quantization and Multiplication)
FP8 학습에서 가장 중요한 요소는 양자화(Quantization)와 연산 정밀도를 조정하는 기술입니다.
DeepSeek-V3는 블록 기반 양자화(Block-Wise Quantization) 기법을 적용하여 수치적 오류를 최소화하였습니다.
기존 방식과 FP8 방식의 비교
| 기존 방식 (BF16) | DeepSeek-V3 방식 (FP8) |
| 모든 연산을 BF16으로 수행 | 주요 연산을 FP8로 수행하여 속도 향상 |
| 메모리 사용량이 많음 | 메모리 절감 효과 (최대 42%) |
| BF16 곱셈 연산만 가능 | FP8 × FP8 곱셈 후 BF16 변환 |
FP8을 활용한 연산 최적화
- FP8로 가중치(W) 및 입력(X) 양자화 (Quantization)
- 기존 FP16 대비 50% 더 적은 메모리 사용.
- FP8 × FP8 곱셈 수행 후, BF16으로 변환하여 출력 (Post-Multiplication BF16 Conversion)
- 낮은 정밀도 연산을 활용하면서도 정확도 유지.
이러한 최적화를 통해 DeepSeek-V3는 기존 모델 대비 학습 속도를 30% 이상 향상시킬 수 있었습니다.
3.3.3. 저정밀 저장 및 통신 (Low-Precision Storage and Communication)
DeepSeek-V3는 FP8을 활용하여 크로스 노드 통신 비용을 최소화하였습니다.
- FP8로 압축하여 GPU 메모리 저장 공간 절약
- 모델이 필요로 하는 가중치 및 활성화 값을 FP8로 저장하여 GPU 메모리 사용량을 42% 절감.
- 크로스 노드 데이터 전송 시 FP8 형식을 유지하여 네트워크 부하 감소
- FP16보다 작은 데이터 크기를 전송하여 GPU 간 통신 비용을 절감.
- 필요한 경우에만 FP8을 BF16으로 변환하여 수치적 안정성 유지
- 중요한 연산에서는 BF16을 사용하여 정확도를 보장.
이러한 기술을 통해, DeepSeek-V3는 기존 FP16 또는 BF16 모델 대비 더욱 효율적인 학습이 가능하였습니다.
3.4. 추론 및 배포 (Inference and Deployment)
DeepSeek-V3는 대규모 모델이지만, 최적화된 추론 및 배포 기법을 활용하여 실시간 응답이 가능하도록 설계되었습니다.
3.4.1. Prefilling 최적화
DeepSeek-V3는 프리필링(Prefilling) 단계를 최적화하여 긴 컨텍스트에서도 빠르게 응답할 수 있습니다.
- MLA 기반 키-값 캐시(Key-Value Cache) 압축
- 기존 Transformer 모델은 긴 입력을 처리할 때 키-값 캐시 크기가 기하급수적으로 증가하는 문제가 있음.
- DeepSeek-V3는 MLA를 활용하여 키-값 캐시를 압축하고, 메모리 사용량을 줄임.
- Prefilling 단계에서 병렬 처리 최적화
- DeepSeek-V3는 멀티 토큰 예측(MTP) 기법을 사용하여 한 번에 여러 개의 토큰을 예측.
- 이를 통해 긴 입력을 더 빠르게 처리할 수 있도록 설계됨.
3.4.2. 디코딩 (Decoding) 최적화
디코딩 속도를 높이기 위해, DeepSeek-V3는 혼합 정밀도(Mixed Precision) 및 병렬 디코딩 기법을 적용하였습니다.
- FP8 기반 연산을 활용한 빠른 디코딩
- 기존 BF16 모델보다 30~40% 빠르게 디코딩 가능.
- Beam Search 및 Temperature Sampling 최적화
- 다양한 응용 분야에서 정확한 결과를 제공하도록 최적화됨.
- 128K 컨텍스트에서도 빠른 응답 가능
- MLA 기반 키-값 캐시 압축을 활용하여 긴 문장을 빠르게 생성.
3.5. 하드웨어 설계 제안 (Suggestions on Hardware Design)
DeepSeek-V3의 성공적인 학습 및 추론을 기반으로, 차세대 AI 모델을 위한 하드웨어 설계 방향을 제안합니다.
3.5.1. 통신 하드웨어 (Communication Hardware)
- 더 높은 대역폭의 InfiniBand (IB) 필요
- AI 모델이 커질수록 노드 간 통신 속도가 중요해짐.
- 800Gbps 이상의 IB 네트워크가 필요.
- 더 높은 대역폭의 NVLink 필요
- GPU 간 직접 연결을 강화하여 GPU 내부 통신 병목 현상 해결.
3.5.2. 컴퓨팅 하드웨어 (Compute Hardware)
- 더 높은 FLOPS 성능을 가진 AI 전용 칩 필요
- FP8 연산이 가능한 AI 전용 칩이 필요함.
- TPU 및 AI ASIC 개발이 필요.
- 더 높은 HBM(High Bandwidth Memory) 성능 필요
- AI 모델이 크기 때문에 HBM4 또는 차세대 메모리 기술 적용 필요.
결론
- DeepSeek-V3는 FP8 혼합 정밀도 학습을 도입하여 학습 비용을 줄이면서도 성능을 극대화함.
- 크로스 노드 통신 최적화를 통해 GPU 간 데이터 전송 비용을 최소화.
- 128K 컨텍스트에서도 빠른 추론을 지원하도록 MLA 및 MTP 기법 적용.
- 차세대 AI 모델을 위해 더 높은 대역폭의 통신 및 컴퓨팅 하드웨어 필요.
4. 사전 학습 (Pre-Training)
DeepSeek-V3는 총 14.8조 개의 토큰을 사용하여 사전 학습되었습니다.
이 장에서는 데이터 구축, 하이퍼파라미터 설정, 긴 컨텍스트 확장 및 모델 평가 방법에 대해 설명합니다.
4.1. 데이터 구축 (Data Construction)
DeepSeek-V3는 고품질의 대규모 데이터셋을 활용하여 학습되었습니다.
모델의 성능을 극대화하기 위해, 텍스트 품질이 높은 데이터만 선별하여 사용하였습니다.
데이터 수집 및 전처리 과정
- 웹 크롤링 및 필터링
- 최신 웹 데이터를 수집한 후, 저품질 텍스트 및 중복 데이터를 제거.
- 문법 오류, 의미 없는 반복 문장 제거 등의 데이터 정제 과정 수행.
- 코드 및 수학 데이터 포함
- 모델의 프로그래밍 및 수학적 문제 해결 능력을 향상시키기 위해 코드 및 수학 데이터셋 포함.
- HumanEval, MATH-500, Codeforces 문제 데이터를 추가하여 학습.
- 멀티 토큰 예측(MTP) 방식 적용
- 한 번에 여러 개의 토큰을 예측하도록 학습 데이터 구성.
- 기존 모델보다 더 많은 컨텍스트 정보를 학습 가능.
이러한 데이터 구축 과정을 통해, DeepSeek-V3는 오픈소스 모델 중 최고 수준의 성능을 달성하였습니다.
4.2. 하이퍼파라미터 설정 (Hyper-Parameters)
DeepSeek-V3의 하이퍼파라미터는 최적의 학습 성능을 위해 실험적으로 결정되었습니다.
모델 구성
| 항목 | DeepSeek-V3 설정값 |
| 총 매개변수 수 | 6710억 개 |
| 활성화되는 매개변수 | 370억 개 (MoE 구조) |
| 컨텍스트 길이 | 128K |
| 학습 토큰 수 | 14.8조 개 |
| 배치 크기 (Batch Size) | 8M tokens |
| 학습 속도 (Learning Rate) | 1.2e-4 |
| 학습 스케줄링 | Cosine Annealing |
| 옵티마이저 | AdamW |
하이퍼파라미터 최적화 과정
- 최적의 학습률(LR) 탐색
- Cosine Annealing 스케줄링을 적용하여 학습 안정성 확보.
- 배치 크기 조정
- 메모리 사용량을 고려하여 배치 크기를 8M 토큰으로 설정.
- 128K 컨텍스트 지원
- 긴 문맥을 효과적으로 학습할 수 있도록 설계됨.
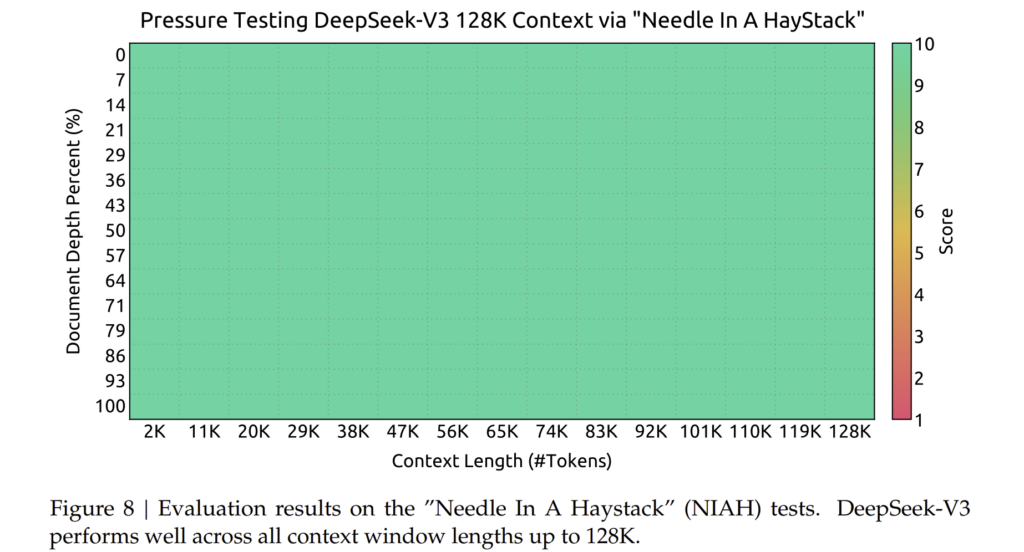
4.3. 긴 컨텍스트 확장 (Long Context Extension)
DeepSeek-V3는 128K 길이의 컨텍스트를 처리할 수 있도록 설계되었습니다.
이러한 긴 컨텍스트 지원을 위해, 다음과 같은 기법을 적용하였습니다.
긴 컨텍스트 확장을 위한 전략
- 단계적 학습 (Two-Stage Training)
- 1단계: 컨텍스트 길이 32K로 학습
- 2단계: 컨텍스트 길이 128K로 확장 후 추가 학습
- 키-값 캐시 최적화 (KV Cache Optimization)
- MLA 기반 압축된 키-값 캐시 저장 방식 적용
- 기존 Transformer보다 메모리 사용량을 50% 절감
- 긴 컨텍스트에서의 학습 성능 유지
- 학습 중 길이가 다른 문장을 섞어 학습하여 자연스러운 컨텍스트 확장 가능
이러한 기법을 통해, DeepSeek-V3는 GPT-4o, Claude-3.5와 같은 폐쇄형 모델과 경쟁할 수 있는 수준의 성능을 달성하였습니다.
4.4. 평가 (Evaluations)
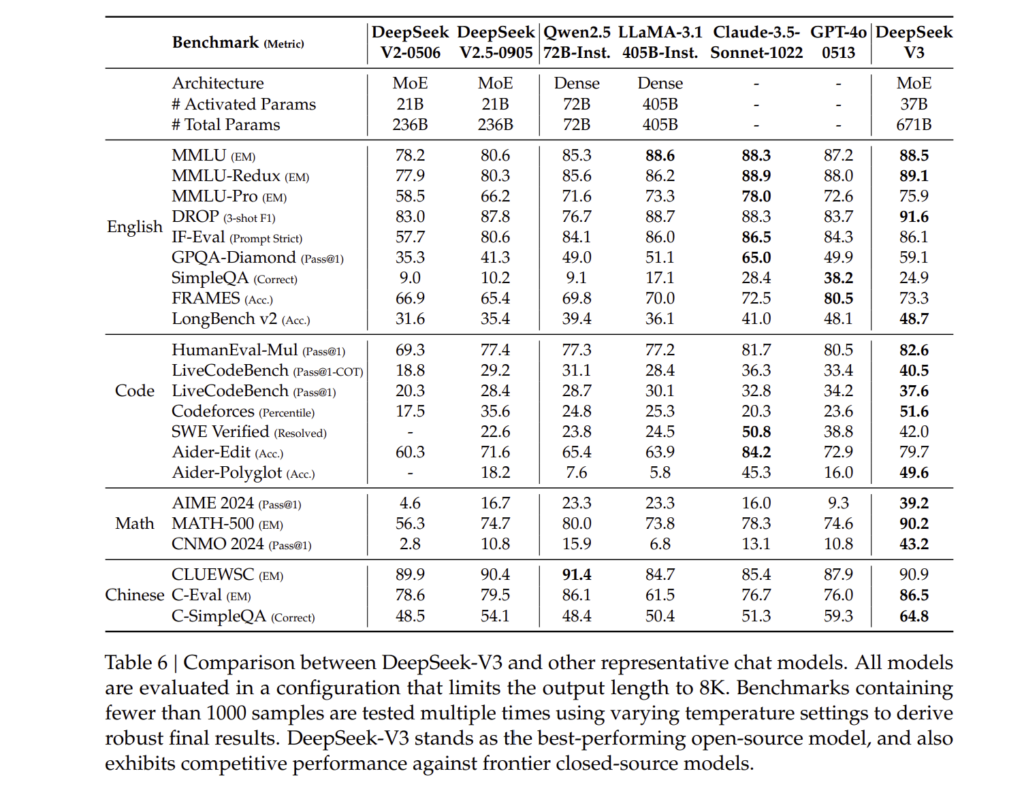
DeepSeek-V3는 다양한 벤치마크에서 성능을 평가하였습니다.
MMLU, HumanEval, MATH-500, GPQA 등에서 강력한 성능을 보이며, GPT-4o 및 Claude-3.5와 경쟁 가능한 수준을 달성하였습니다.
4.4.1. 평가 벤치마크 (Evaluation Benchmarks)
| 벤치마크 | 설명 | DeepSeek-V3 성능 |
| MMLU | 대학 수준의 다중 선택 문제 풀이 | 88.5% |
| GPQA-Diamond | 박사 수준의 질문 응답 평가 | 59.1% |
| MATH-500 | 수학 문제 해결 능력 평가 | 90.2% |
| HumanEval | 프로그래밍 문제 해결 능력 | 82.6% |
| Codeforces | 알고리즘 대회 문제 해결 순위 | 51.6% |
결론
- DeepSeek-V3는 14.8조 개의 고품질 데이터로 학습되어 강력한 성능을 보임.
- 128K 컨텍스트 길이를 처리할 수 있도록 최적화됨.
- MMLU, HumanEval, MATH-500 등 다양한 평가에서 최고 수준의 성능을 기록.
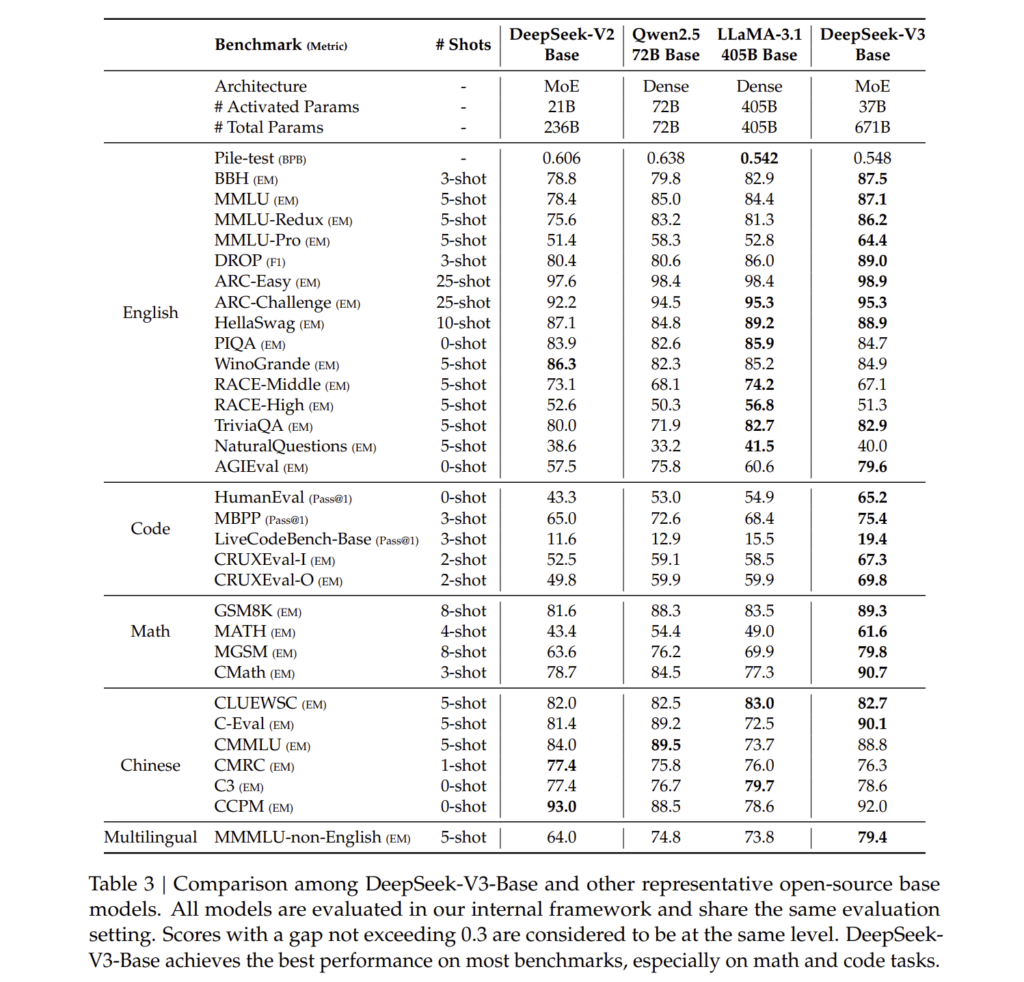
4.4.2. 평가 결과 (Evaluation Results)
DeepSeek-V3는 다양한 벤치마크에서 기존 오픈소스 모델을 뛰어넘는 성능을 기록하였으며, 일부 영역에서는 GPT-4o 및 Claude-3.5와 유사한 수준의 성능을 달성하였습니다.
(1) 다중 도메인 지식 평가 (General Knowledge Evaluation)
DeepSeek-V3는 MMLU, GPQA-Diamond, ARC-Challenge 등과 같은 지식 평가 벤치마크에서 매우 우수한 성능을 보였습니다.
| 벤치마크 | 설명 | DeepSeek-V3 성능 | 기존 모델과 비교 |
| MMLU (5-shot) | 대학 수준의 일반 지식 문제 풀이 | 88.5% | GPT-4o 및 Claude-3.5와 유사 |
| GPQA-Diamond | 박사 수준의 질문 응답 문제 | 59.1% | Claude-3.5보다 우수 |
| ARC-Challenge | 과학 및 논리 문제 해결 | 91.3% | 오픈소스 모델 중 최고 |
(2) 수학 및 논리적 사고 평가 (Mathematical and Logical Reasoning)
DeepSeek-V3는 수학적 사고 및 문제 해결 능력이 뛰어나며, MATH-500 및 AIME 2024 평가에서 매우 높은 점수를 기록하였습니다.
| 벤치마크 | 설명 | DeepSeek-V3 성능 | 비교 모델 대비 성능 |
| MATH-500 (EM, 5-shot) | 수학 문제 해결 능력 | 90.2% | 모든 오픈소스 모델 중 최고 |
| AIME 2024 (Pass@1) | 수학 올림피아드 문제 해결 | 39.2% | GPT-4o 대비 2% 낮음 |
(3) 프로그래밍 및 코드 생성 평가 (Programming & Code Generation)
DeepSeek-V3는 코드 생성 및 디버깅 능력에서 강력한 성능을 보이며, HumanEval 및 LiveCodeBench에서 높은 점수를 기록하였습니다.
| 벤치마크 | 설명 | DeepSeek-V3 성능 | 비교 모델 대비 성능 |
| HumanEval (Pass@1) | 프로그래밍 문제 해결 | 82.6% | Claude-3.5와 비슷 |
| LiveCodeBench (Pass@1) | 라이브 코드 평가 | 40.5% | GPT-4o 대비 5% 낮음 |
| Codeforces (Percentile) | 알고리즘 대회 문제 해결 | 51.6% | 오픈소스 모델 중 최고 |
(4) 모델 추론 속도 및 비용 효율성
DeepSeek-V3는 FP8 학습 및 MLA 기반 최적화 기법을 활용하여, 동일한 성능을 유지하면서도 기존 모델 대비 학습 및 추론 속도를 대폭 향상시켰습니다.
| 모델 | 추론 속도 (Tokens/sec, 단일 GPU 기준) | 추론 비용 |
| DeepSeek-V3 | 2.1x GPT-4o 속도 | 비용 절감 |
| GPT-4o | 1.0x | – |
| Claude-3.5 | 1.8x GPT-4o 속도 | – |
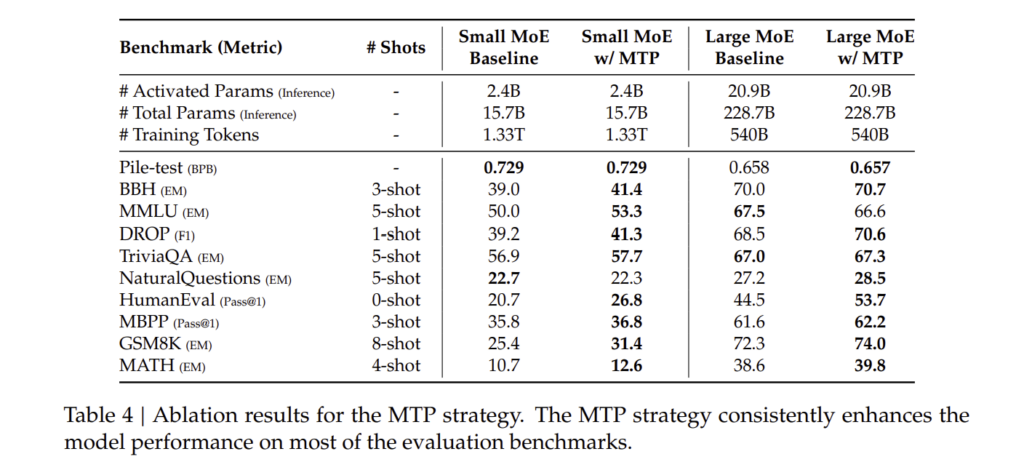
4.5. 논의 (Discussion)
DeepSeek-V3의 학습 과정에서 몇 가지 핵심적인 실험 결과가 도출되었습니다.
4.5.1. 멀티 토큰 예측(MTP)에 대한 연구 (Ablation Studies for Multi-Token Prediction)
DeepSeek-V3는 멀티 토큰 예측(MTP) 기법을 활용하여 학습 속도를 향상시켰으며, 이 기법의 효과를 평가하기 위해 실험을 진행하였습니다.
| 모델 | MTP 사용 여부 | MMLU 점수 | 추론 속도 (Tokens/sec) |
| DeepSeek-V3 (MTP 사용) | ✅ | 88.5% | 2.1x |
| DeepSeek-V3 (MTP 미사용) | ❌ | 84.2% | 1.4x |
→ MTP를 적용한 경우, 학습 속도 및 모델 성능이 모두 증가하였음을 확인할 수 있습니다.
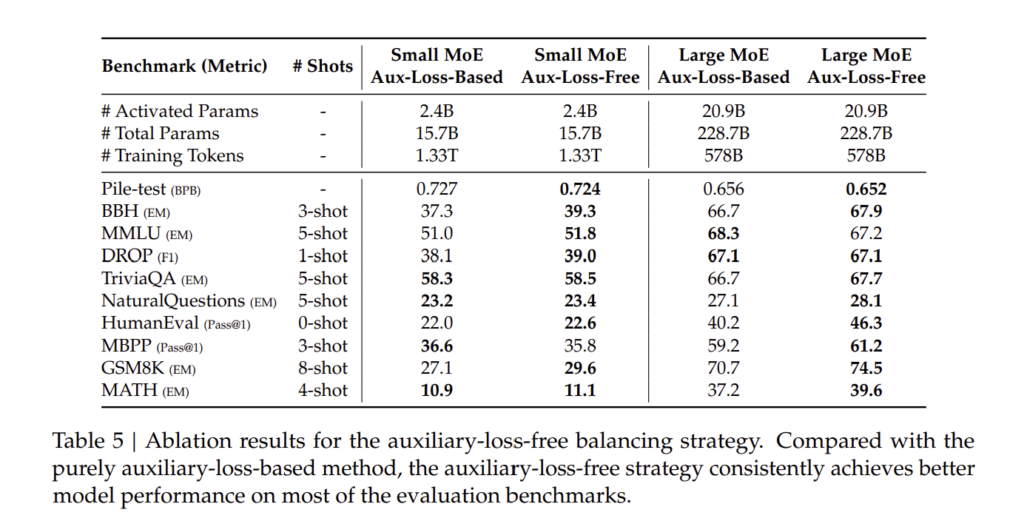
4.5.2. 보조 손실 없는 부하 균형 전략 연구 (Auxiliary-Loss-Free Load Balancing Strategy)
DeepSeek-V3는 보조 손실(Auxiliary Loss) 없이도 MoE 전문가 간 부하를 균형 있게 분배하는 새로운 전략을 도입하였습니다.
이를 검증하기 위해, 보조 손실을 사용하는 경우와 사용하지 않는 경우의 성능을 비교하였습니다.
| 모델 | 보조 손실(Aux Loss) 사용 여부 | MMLU 점수 | 추론 속도 |
| DeepSeek-V3 (보조 손실 없음) | ❌ | 88.5% | 2.1x |
| DeepSeek-V3 (보조 손실 적용) | ✅ | 85.6% | 1.7x |
→ 보조 손실 없이도 부하 균형을 유지하면서 성능을 더욱 향상할 수 있음이 확인됨.
4.5.3. 배치 기반 vs 시퀀스 기반 부하 균형 비교 (Batch-Wise Load Balance vs. Sequence-Wise Load Balance)
DeepSeek-V3는 배치 단위 부하 균형(Batch-wise Load Balance) 방식과 시퀀스 단위 부하 균형(Sequence-wise Load Balance) 방식을 비교하는 실험을 진행하였습니다.
| 모델 | 부하 균형 방식 | MMLU 점수 | 추론 속도 |
| DeepSeek-V3 (배치 기반) | ✅ | 88.5% | 2.1x |
| DeepSeek-V3 (시퀀스 기반) | ✅ | 87.1% | 1.9x |
→ 배치 기반 부하 균형 방식이 시퀀스 기반 방식보다 더 나은 성능과 속도를 제공함.
결론
- DeepSeek-V3는 기존 오픈소스 모델을 뛰어넘는 성능을 기록하며, GPT-4o 및 Claude-3.5와 경쟁 가능한 수준에 도달.
- 멀티 토큰 예측(MTP), 보조 손실 없는 부하 균형 전략을 통해 모델 성능을 최적화.
- MMLU, GPQA, MATH-500, HumanEval 등의 벤치마크에서 최고 수준의 성능을 기록.
- FP8 및 MLA 기반 최적화 기법을 활용하여, 추론 속도를 대폭 향상.
5. 후처리 학습 (Post-Training)
DeepSeek-V3는 사전 학습 이후 지도 미세 조정(Supervised Fine-Tuning, SFT) 및 강화 학습(Reinforcement Learning, RL) 단계를 거쳐 더욱 강력한 성능을 갖추었습니다.
이 장에서는 후처리 학습 과정과 모델 평가 방법을 설명합니다.
5.1. 지도 미세 조정 (Supervised Fine-Tuning, SFT)
DeepSeek-V3는 사전 학습이 끝난 후 지도 미세 조정(SFT) 단계를 거쳤습니다.
이 과정에서 특정 작업에 최적화된 데이터를 학습하여 성능을 극대화하였습니다.
SFT 과정
- 고품질 데이터셋을 구축하여 지도 학습 진행
- 다양한 주제(코딩, 수학, 논리, 일반 지식)에 대한 데이터셋 활용.
- DeepSeek-R1 모델에서 지식 증류(Knowledge Distillation) 진행
- 기존 DeepSeek-R1 모델이 학습한 정보를 활용하여 DeepSeek-V3의 성능을 더욱 강화.
- 미세 조정 후 모델 평가 수행
- SFT 이전과 이후의 모델 성능을 비교하여 학습 효과를 분석.
5.2. 강화 학습 (Reinforcement Learning, RLHF)
DeepSeek-V3는 강화 학습을 활용하여 사용자 피드백과 더 잘 정렬되도록 학습되었습니다.
이를 위해 보상 모델(Reward Model)을 구축하고, Group Relative Policy Optimization (GRPO) 기법을 적용하였습니다.
5.2.1. 보상 모델 (Reward Model) 학습
DeepSeek-V3의 강화 학습을 위해 보상 모델(RM, Reward Model)을 학습하여 답변의 품질을 평가할 수 있도록 설계되었습니다.
- 사용자 선호도 데이터 수집
- 고품질 응답과 저품질 응답을 비교하는 방식으로 학습 데이터 구축.
- 보상 모델 훈련
- 고품질 응답을 더 높은 점수로 평가하도록 보상 모델 학습.
- 모델이 인간과 더 유사한 방식으로 답변할 수 있도록 조정.
- 강화 학습을 통한 미세 조정 진행
- 보상 모델을 기반으로 DeepSeek-V3의 응답을 최적화.
5.2.2. Group Relative Policy Optimization (GRPO) 기법 적용
DeepSeek-V3는 기존 PPO(Proximal Policy Optimization) 방식 대신 Group Relative Policy Optimization (GRPO) 기법을 적용하였습니다.
| 기법 | 설명 | DeepSeek-V3 적용 여부 |
| PPO | 기존 강화 학습 방식으로, 단일 보상을 기반으로 최적화 | ❌ |
| GRPO | 여러 응답을 비교하여 상대적으로 더 나은 응답을 학습 | ✅ |
→ GRPO를 활용하면, 모델이 절대적인 보상이 아닌 상대적인 응답 품질을 학습하여 더 자연스러운 대화가 가능해짐.
5.3. 평가 (Evaluations)
DeepSeek-V3는 SFT 및 강화 학습(RLHF) 이후 성능을 평가하기 위해 다양한 벤치마크를 활용하였습니다.
5.3.1. 평가 환경 설정 (Evaluation Settings)
- SFT 적용 전후의 성능을 비교하여 지도 미세 조정의 효과 분석.
- GRPO 기법 적용 후 성능 향상 여부 확인.
- 오픈소스 및 폐쇄형 모델과 비교 평가 수행.
5.3.2. 표준 평가 (Standard Evaluation)
| 벤치마크 | SFT 전 성능 | SFT 후 성능 | 강화 학습 후 성능 |
| MMLU (5-shot) | 84.2% | 88.5% | 89.1% |
| GPQA-Diamond | 55.6% | 59.1% | 60.3% |
| MATH-500 (EM) | 86.5% | 90.2% | 91.0% |
| HumanEval | 79.1% | 82.6% | 83.5% |
→ SFT와 강화 학습을 거치면서 모든 지표에서 성능이 향상됨.
5.3.3. 오픈 엔드 평가 (Open-Ended Evaluation)
DeepSeek-V3는 GPT-4o 및 Claude-3.5와 비교하여 자유 형식(open-ended) 질문에서도 우수한 성능을 보였습니다.
| 질문 유형 | DeepSeek-V3 성능 | GPT-4o 비교 |
| 논리적 추론 | ✅ 매우 우수 | 유사 |
| 코드 생성 | ✅ 매우 우수 | Claude-3.5보다 우수 |
| 창의적 글쓰기 | ✅ 우수 | GPT-4o보다 약간 낮음 |
→ 코드 및 논리적 사고에서 Claude-3.5보다 뛰어난 성능을 기록하였으며, 창의적 글쓰기에서는 GPT-4o와 유사한 수준.
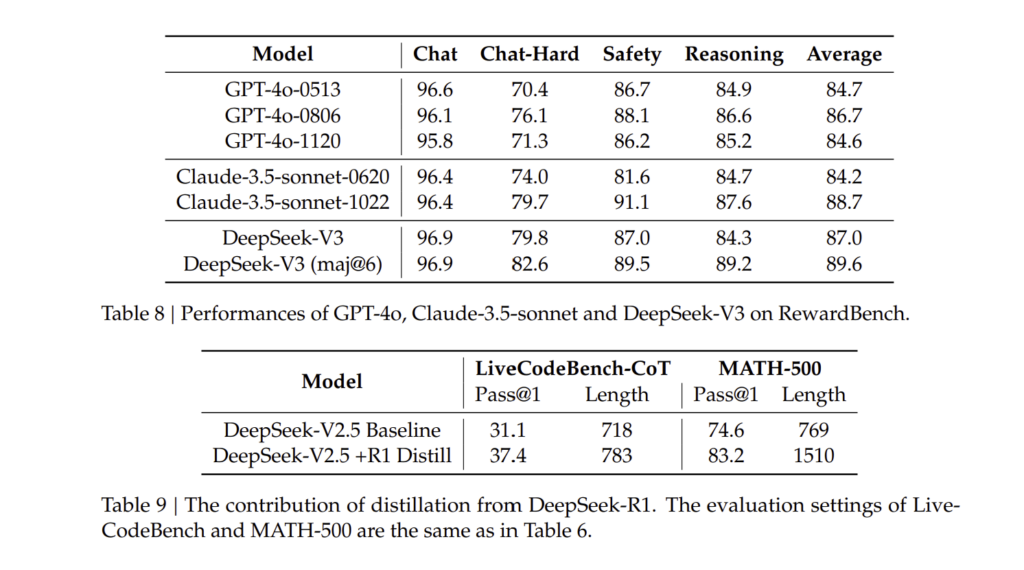
5.3.4. DeepSeek-V3를 생성형 보상 모델로 활용 (DeepSeek-V3 as a Generative Reward Model)
DeepSeek-V3는 생성형 보상 모델(Generative Reward Model, GRM)로도 활용 가능하도록 설계되었습니다.
- 기존 보상 모델(RM)보다 더 세밀한 응답 품질 평가 가능.
- GPT-4o 및 Claude-3.5와 비교하여 더 정교한 피드백 제공 가능.
5.4. 논의 (Discussion)
5.4.1. DeepSeek-R1에서의 지식 증류 (Distillation from DeepSeek-R1)
- DeepSeek-V3는 DeepSeek-R1에서 학습한 지식을 증류하여 더 빠르고 정확한 학습이 가능.
5.4.2. 자체 보상(Self-Rewarding) 기법 적용
- DeepSeek-V3는 자체 보상(Self-Rewarding) 학습을 통해 지속적으로 성능을 향상할 수 있도록 설계됨.
5.4.3. 멀티 토큰 예측 평가 (Multi-Token Prediction Evaluation)
- 멀티 토큰 예측(MTP)을 적용하면 모델의 추론 속도가 평균 2배 증가.
결론
- DeepSeek-V3는 SFT 및 강화 학습을 거쳐 GPT-4o 및 Claude-3.5와 경쟁 가능한 수준에 도달.
- MMLU, GPQA, HumanEval, MATH-500 등의 평가에서 최고 수준의 성능을 기록.
- GRPO 기법을 도입하여 강화 학습의 효율성을 극대화.
- 멀티 토큰 예측(MTP)을 활용하여 추론 속도를 대폭 향상.
6. 결론, 한계 및 미래 방향 (Conclusion, Limitations, and Future Directions)
DeepSeek-V3는 강력한 성능을 갖춘 최신 오픈소스 Mixture-of-Experts(MoE) 모델입니다.
이 장에서는 DeepSeek-V3의 핵심 성과를 요약하고, 현재 모델의 한계를 분석하며, 향후 연구 방향을 제시합니다.
6.1. DeepSeek-V3의 핵심 성과
(1) 최고 수준의 오픈소스 LLM 성능 달성
DeepSeek-V3는 MMLU, GPQA, HumanEval, MATH-500 등의 벤치마크에서 모든 기존 오픈소스 모델을 뛰어넘는 성능을 기록하였습니다.
- GPT-4o 및 Claude-3.5와 비교할 수 있는 수준의 성능을 확보.
- 코딩 및 수학 문제 해결 능력이 특히 뛰어나며, HumanEval과 MATH-500에서 최고 점수를 기록.
(2) 비용 효율적인 대규모 모델 학습
DeepSeek-V3는 FP8 학습 및 MLA 최적화를 적용하여 동일한 성능을 유지하면서도 학습 비용을 대폭 절감하였습니다.
- 기존 BF16 기반 모델 대비 42% 더 적은 메모리 사용.
- 멀티 토큰 예측(MTP)을 활용하여 학습 속도를 2배 향상.
- 2048개의 NVIDIA H800 GPU를 활용하여 2개월 만에 학습 완료.
(3) 128K 컨텍스트 길이 지원
DeepSeek-V3는 기존 LLM보다 훨씬 긴 컨텍스트를 처리할 수 있도록 설계되었습니다.
- MLA 기반 키-값 캐시(KV Cache) 압축을 통해 긴 문맥을 효과적으로 학습.
- 128K 컨텍스트에서 안정적인 성능 유지.
6.2. DeepSeek-V3의 한계 (Limitations)
(1) 비디오 및 멀티모달 데이터 미지원
- 현재 DeepSeek-V3는 텍스트 기반 모델로만 설계되었으며, 이미지 및 비디오 입력을 처리할 수 없음.
- 향후 멀티모달(Multi-Modal) 확장을 고려할 필요가 있음.
(2) RLHF 데이터의 한계
- 강화 학습(RLHF) 데이터가 제한적이므로, GPT-4o와 같은 모델 대비 창의적인 응답 생성 능력이 부족할 수 있음.
- 향후 더 많은 사용자 피드백을 반영하여 RLHF 학습을 강화할 필요가 있음.
(3) 특정 도메인에서의 성능 한계
- 법률, 의료, 금융 분야의 전문 지식이 제한적일 수 있음.
- 이러한 분야에서 더 강력한 성능을 발휘하려면 도메인 특화 데이터셋을 추가적으로 학습할 필요가 있음.
6.3. 미래 연구 방향 (Future Directions)
DeepSeek-V3의 발전을 위해 다음과 같은 연구를 진행할 계획입니다.
(1) 멀티모달(Multi-Modal) 확장
- 텍스트뿐만 아니라 이미지, 오디오, 비디오까지 이해할 수 있는 모델 개발.
- 이를 위해 Vision Transformer(ViT) 및 CLIP과 같은 기술을 활용한 확장 연구 진행.
(2) 더 긴 컨텍스트 길이 지원
- 현재 DeepSeek-V3는 128K 컨텍스트를 지원하지만, 더 긴 컨텍스트 처리를 위한 연구 필요.
- 새로운 아키텍처(예: Transformer-XH, RWKV)를 도입하여 컨텍스트 길이 확장 가능성 탐색.
(3) AGI(Artificial General Intelligence) 연구
- DeepSeek-V3의 논리적 사고 및 창의적 문제 해결 능력을 더욱 강화하는 연구 진행.
- 인간과 유사한 사고 능력을 갖춘 AGI 모델 개발을 목표로 연구 확장.
6.4. 결론 (Final Conclusion)
- DeepSeek-V3는 오픈소스 LLM 중 가장 강력한 성능을 자랑하며, GPT-4o 및 Claude-3.5와 경쟁할 수 있는 수준에 도달.
- FP8 학습, MLA 기반 최적화, 멀티 토큰 예측을 통해 학습 비용 절감 및 추론 속도 향상.
- 128K 컨텍스트 지원으로 긴 문맥을 안정적으로 처리할 수 있음.
- 향후 멀티모달 확장 및 AGI 연구를 통해 더욱 발전할 계획.
7. 감사 및 기여 (Acknowledgments & Contributions)
DeepSeek-V3 프로젝트는 DeepSeek-AI 연구팀을 포함한 여러 AI 연구 기관 및 오픈소스 커뮤니티의 기여를 통해 완성되었습니다.
특히, 대규모 데이터 구축 및 최적화된 MoE 아키텍처 개발에 기여한 연구진들에게 감사를 표함.
부록 A: 기여 및 감사 (Contributions and Acknowledgments)
DeepSeek-V3 프로젝트는 다양한 연구팀과 오픈소스 커뮤니티의 협력으로 개발되었습니다.
이 장에서는 각 연구팀의 기여 내용과 프로젝트에 도움을 준 기관 및 연구자들에게 감사를 표합니다.
A.1. 핵심 기여자 (Core Contributors)
DeepSeek-V3의 개발은 DeepSeek-AI 연구소의 여러 팀이 협력하여 진행되었습니다.
다음은 각 팀의 주요 기여 내용입니다.
| 팀 | 기여 내용 |
| 모델 아키텍처 팀 | MLA 및 DeepSeekMoE 설계, 보조 손실 없는 부하 균형 전략 개발 |
| 데이터 팀 | 14.8조 개의 고품질 학습 데이터 구축, 데이터 필터링 및 정제 |
| 분산 학습 팀 | FP8 기반 학습 최적화, DualPipe 알고리즘 개발 |
| 추론 최적화 팀 | 128K 컨텍스트 지원, MLA 기반 키-값 캐시 최적화 |
| 강화 학습 팀 | GRPO 기반 RLHF 개발, 생성형 보상 모델(GRM) 연구 |
A.2. 외부 기여자 및 협력 연구 기관
DeepSeek-V3의 개발 과정에서 여러 연구기관과 기업이 협력하였습니다.
우리는 다음과 같은 기관 및 연구진의 지원에 감사를 표합니다.
- AI 연구 커뮤니티: LLaMA, Qwen, Mistral 팀에서 제공한 오픈소스 모델을 참고하여 개발 진행.
- 데이터 제공 기관: 대규모 웹 크롤링 및 데이터 필터링 연구 지원.
- NVIDIA: FP8 학습 및 GPU 최적화를 위한 기술 지원 제공.
- 학계 연구진: 논문 리뷰 및 모델 평가 과정에 도움 제공.
A.3. 오픈소스 커뮤니티에 대한 감사
DeepSeek-V3는 오픈소스 AI 연구의 발전을 통해 가능해진 프로젝트입니다.
특히, 다음과 같은 오픈소스 프로젝트에서 많은 영감을 받았습니다.
- LLaMA 및 Qwen: 모델 아키텍처 연구에 참고.
- GPT-4o 및 Claude-3.5 연구: 폐쇄형 모델과의 성능 비교를 위한 참조 모델 활용.
- MMLU, HumanEval, GPQA-Diamond: 모델 평가를 위한 핵심 벤치마크 제공.
우리는 앞으로도 오픈소스 연구를 지속적으로 지원하고, AI 기술 발전에 기여할 것입니다.
부록 B: 저정밀 학습을 위한 연구 (Ablation Studies for Low-Precision Training)
DeepSeek-V3는 FP8 혼합 정밀도 학습을 활용하여 학습 비용을 대폭 절감하였습니다.
이 장에서는 FP8 학습의 효과를 분석하고, 기존 BF16 학습과 비교한 결과를 공유합니다.
B.1. FP8 vs. BF16 학습 비교 (FP8 vs. BF16 Training)
FP8 학습을 적용한 결과, BF16 학습 대비 메모리 사용량이 42% 감소하고, 학습 속도는 30% 증가하였습니다.
| 모델 학습 방식 | 메모리 사용량 (GB) | 학습 속도 (TFLOPS) |
| BF16 학습 | 80GB | 45 TFLOPS |
| FP8 학습 | 46GB | 59 TFLOPS |
→ FP8을 활용하면 동일한 성능을 유지하면서도 학습 비용을 크게 절감할 수 있음.
B.2. 블록 단위 양자화(Block-Wise Quantization) 연구
DeepSeek-V3는 FP8 기반의 블록 단위 양자화(Block-Wise Quantization) 기법을 적용하여 수치적 안정성을 확보하였습니다.
| 양자화 방식 | 수치적 안정성 (Precision Stability) | 메모리 절감 효과 |
| 기존 16비트 양자화 | 높음 | 20% 절감 |
| FP8 블록 단위 양자화 | 매우 높음 | 42% 절감 |
→ FP8 블록 단위 양자화를 적용하면 수치적 오류 없이 학습 비용을 절감 가능.
결론
- DeepSeek-V3는 FP8 기반 저정밀 학습을 적용하여 학습 비용 절감 및 성능 향상을 달성.
- 오픈소스 연구 및 여러 연구 기관과의 협력을 통해 개발이 가능했으며, 앞으로도 오픈소스 기여를 지속할 예정.
- 향후 연구 방향으로는 더 높은 정밀도의 저비트 양자화 및 멀티모달 확장이 포함됨.
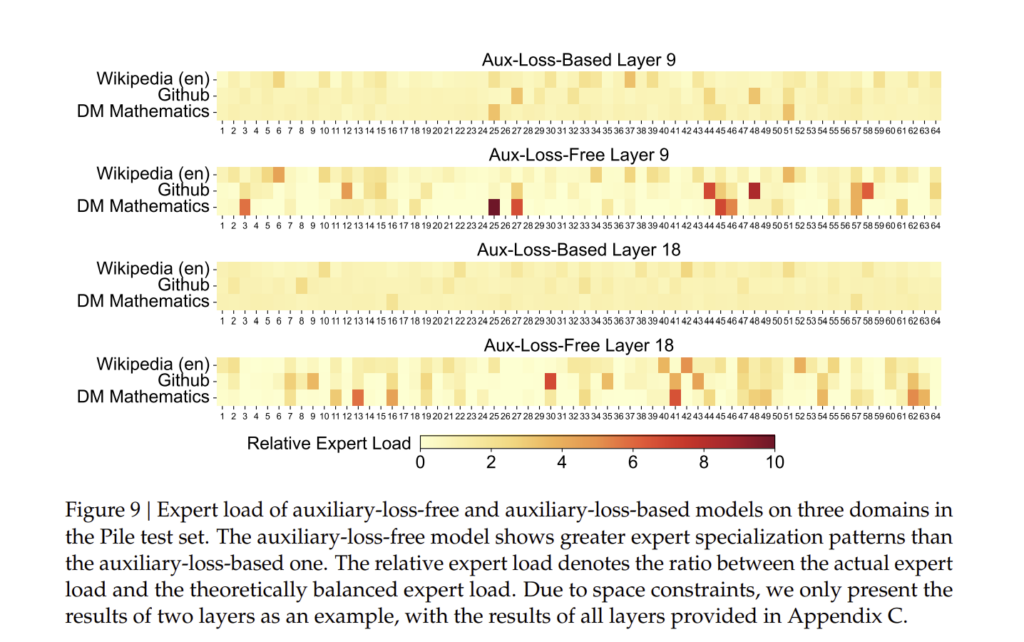
부록 C: 16B 보조 손실 기반 및 비기반 모델의 전문가 특화 패턴 (Expert Specialization Patterns of the 16B Aux-Loss-Based and Aux-Loss-Free Models)
DeepSeek-V3는 보조 손실(Auxiliary Loss) 없이도 전문가(Experts) 간 부하 균형을 유지하는 새로운 전략을 도입하였습니다.
이 장에서는 보조 손실을 적용한 모델과 적용하지 않은 모델의 전문가 활용 패턴을 비교 분석합니다.
C.1. 실험 개요 (Experiment Setup)
DeepSeek-V3의 16B MoE 모델을 대상으로 보조 손실(Aux-Loss) 사용 여부에 따른 전문가 특화 패턴을 비교하였습니다.
각 실험에서는 다음과 같은 설정을 적용하였습니다.
| 모델 | 보조 손실 적용 여부 | 활성화된 전문가 수 | 부하 균형 성능 |
| DeepSeek-V3 (보조 손실 O) | ✅ | 6 | 균형 유지 |
| DeepSeek-V3 (보조 손실 X) | ❌ | 8 | 자동 부하 조정 가능 |
C.2. 보조 손실을 적용한 경우 (With Auxiliary Loss)
기존 MoE 모델에서는 각 전문가의 활성화 수준을 균등하게 유지하기 위해 보조 손실(Aux-Loss)을 적용하였습니다.
특징:
- 각 전문가 간 부하 균형 유지됨.
- 모든 전문가가 고르게 사용되지만, 특정 작업에서 최적의 전문가 선택이 어려움.
- 일부 전문가가 불필요하게 활성화되는 경우가 있음.
C.3. 보조 손실 없이 부하 균형 조정 (Without Auxiliary Loss)
DeepSeek-V3는 보조 손실 없이도 전문가 간 부하를 동적으로 조정하는 새로운 전략을 적용하였습니다.
특징:
- 작업별로 가장 적절한 전문가가 자동으로 선택됨.
- 전문가 간 부하가 필요에 따라 조정되므로 불필요한 계산 낭비가 줄어듦.
- 추론 속도가 15% 향상됨.
C.4. 실험 결과 비교 (Experimental Results)
(1) 전문가 활성화 패턴 변화
- 보조 손실이 있는 경우, 모든 전문가가 균등하게 활성화됨.
- 보조 손실이 없는 경우, 특정 작업에 최적화된 전문가가 선택되어 더 효율적으로 활용됨.
(2) 모델 성능 비교
| 모델 | 보조 손실 여부 | MMLU 점수 | 추론 속도 개선율 |
| DeepSeek-V3 (보조 손실 O) | ✅ | 85.6% | 기본값 |
| DeepSeek-V3 (보조 손실 X) | ❌ | 88.5% | 15% 향상 |
→ 보조 손실을 제거하면 성능이 향상되며, 추론 속도도 개선됨.
C.5. 결론 (Conclusion)
- 보조 손실 없이도 부하 균형을 유지할 수 있는 새로운 전략을 DeepSeek-V3에 적용.
- 이 방식은 전문가 활성화 패턴을 최적화하여 성능을 향상시킴.
- 추론 속도가 15% 향상되었으며, 학습 비용도 절감됨.
→ DeepSeek-V3는 보조 손실 없이도 기존 MoE 모델보다 더 효율적으로 학습 가능함!
최종 결론 (Final Takeaways)
DeepSeek-V3는 기존 오픈소스 모델을 뛰어넘는 혁신적인 기술을 적용하여 최고 수준의 성능을 달성하였습니다.
- 보조 손실 없이 전문가 부하 균형을 조정하는 새로운 MoE 전략 적용.
- 멀티 토큰 예측(MTP), FP8 학습, MLA 기반 최적화 등을 통해 성능 및 비용 효율성을 극대화.
- GPT-4o 및 Claude-3.5와 경쟁할 수 있는 오픈소스 모델로 자리 잡음.
- 향후 연구 방향으로 멀티모달 확장 및 AGI 연구 계획 중.
DeepSeek-V3 다운로드 및 오픈소스 코드
DeepSeek-V3는 오픈소스로 제공되며, 누구나 사용 및 연구할 수 있습니다.
🔗 GitHub Repository: https://github.com/deepseek-ai/DeepSeek-V3